

Contents
Intro Primer To WEKA Explorer For Machine Learning
 (6 votes, average: 5.00 out of 5)
(6 votes, average: 5.00 out of 5)Previously, in our Intro Primer For WEKA Machine Learning Software post, we introduced you to Weka and suggested that the Weka Explorer tool could be useful. In this post, we will show you why it is a useful tool for exploring your data, from doing the simplest to the most complex analysis on your data. We will guide you step by step through the analysis of simple problems using Weka Explorer tools for preprocessing, classification, clustering, association, attribute selection, and visualization of data. At the end of the tutorial, you should be able to analyze your own data with Weka Explorer using the various tools and interpret the results.
Hoang Pham Truc Phuong, hptphuong@gmail.com, is the author of this article and he contributes to RobustTechHouse Blog for our Machine Learning column. RobustTechHouse focusses on Mobile App Development in Singapore.
1. Launch Weka Explorer
Click on the “Explorer” button on “Weka GUI Chooser” and the Weka Explorer window will launch.

1.1 Status Box
You should see the status box at the left bottom of the window. It displays messages that keep you informed about what’s going on in Weka. For example, if the Explorer is busy loading a file, the status box will explain as such.

And if Weka explorer is working on data transfers, the status box will show messages for this.

Tips: Right click on the inside of the status box and the sub-menu will appear with two options:
- Memory information. Shows the amount of memory available to Weka.
- Run garbage collection. Force the java garbage collector to search for memory that is no longer needed and frees it up, allowing more space for new tasks. Note that the garbage collector is constantly running as a background task anyway.
1.2 Log Button
Clicking on this button brings up a separate window containing a scrollable text field. Each line of text is stamped with the time it was entered into the log. As you perform actions in Weka, the log keeps a record of what has happened. For people using the command line or the SimpleCLI, the log now also contains the full setup strings for classification, clustering, attribute selection, etc., so it is possible to copy/paste them elsewhere. Options for dataset(s) and, if applicable, the class attribute still needs to be provided by the user (e.g., -t for classifiers or -i and -o for filters).
1.3 Weka Status Icon
To the right of the status box is the Weka status icon. When no processes are running, the bird icon is taking a nap. The number beside the X symbol gives the number of concurrent processes running. When the system is idle it is zero, but it increases as the number of processes increases. When any process is started, the bird icon gets up and starts moving around. If it’s standing but stops moving for a long time, it’s sick: something has gone wrong! In that case you should restart the WEKA Explorer.
2. Preprocessing Data
Data in the real world is frequently dirty. So preprocessing is an important step for successful data mining. Weka has wonderful support for preprocessing data. Here, step-by-step, we take you through how to do data preprocessing on Weka.
2.1 Opening file from a local file system
In the stable version, you can only load some basic file types like *.arff, *. arff.gz, *.names, *.data, *.csv, *.libsvm, *.dat, *.bsi, *.xrff, *.xrff.gz. The developer version supports more file types like: *.json, *.json.gz,…

2.2 Opening a File From a Website
You can directly load data from a given URL. For example, you can choose “open URL” and input this link http://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/contact-lenses.arff

2.3 Reading data from a database
In our last Intro Primer For WEKA Machine Learning Software post on Weka introduction , we mentioned that Weka supports connecting to database management systems (DBMS). From Weka Explorer, you can connect and load data from databases. Here are the steps to load data in Weka Explorer after connecting to a DBMS:
- Choose Open DB
- The URL should read “jdbc:odbc:dbname” where dbname is the name you gave the user DSN.
- Click Connect
- Enter a Query, e.g., “select * from tablename” where tablename is the name of the database table you want to read. Or you could put a more complicated SQL query here instead.
- Click Execute
- When you’re satisfied with the returned data, click OK to load the data into the Preprocess panel.

2.4 Generate artificial data
Weka also supports generation of sample data. Here is the list of some sample data which is supported by Weka.
- Agrawal: Generates a people database and is based on the paper by Agrawal et al.

- BayesNet: Generates random instances based on a Bayes network

- Led24: This generator produces data for a display with 7 LEDs.
- RandomRBF: Data is generated by first creating a random set of centers for each class.
- RDG1: A data generator that produces data randomly by producing a decision list.
2.5 The Current Relation
When the data loaded, the Preprocess panel shows a variety of information. The current relation box, which can be interpreted as a single relational table in database terminology, has three entries:
- Relation. The name of the relation, as given in the file it was loaded from. Filters, described below, modify the name of a relation.
- Instances. The number of instances (data points/records) in the data.
- Attributes. The number of attributes (features) in the data.
The current relation box is labelled as 1 in the screenshot below.

2.6 Working With Attributes
Below the current relation box is a box titled Attributes (labelled as number 2 in screenshot above). There are four buttons, and beneath them is a list of the attributes in the current relation.
The list has three columns:
- No. A number that identifies the attribute in the order they are specified in the data file.
- Selection tick boxes. These allows you to select which attributes are present in the relation.
- Name. The name of the attribute, as it was declared in the data file.
When you click on different rows in the list of attributes, the fields change in the box to the right titled Selected attribute (labelled as number 3 in screenshot above). This box displays the characteristics of the currently highlighted attribute in the list:
- The name of the attribute, the same as that given in the attribute list.
- The type of attribute, most commonly Nominal or Numeric.
- The number and percentage of instances in the data for which this attribute is missing.
- The number of different values that the data contains for this attribute.
- The number and percentage of instances in the data having a value for this attribute that no other instances have.
For example, load the weather.arff and remove a record of temperature attribute at line 4 (by pressing the “Edit” button and edit directly)

Choose “temperature” attribute and you see some static value in selected attribute box:
- Type: Nominal. It means that this is not a numeric but a string type.
- Missing: 1(7%). This means that we lack one value in this attribute, and this is 7% of all records.
- Distinct: 3. This means that there 3 distinct values for records: hot, mild and cold.
- Unique: 0. This means that other instances do not have the same value.
2.7 Working With Filters
WEKA contains filters for discretization, normalization, resampling, attribute selection, transformation and combination of attributes. Sometimes you need to transform your data from numeric to nominal values for some techniques such as association rule mining. In Weka, we can use the “discretize” feature of filters to do this transform.
To explain this feature, we can go through a small example. Load file “weather.numeric.Arff” from Weka’s sample data.

In this data set, the “temperature” attribute is a numeric type and it is a continuous variable. But in some techniques, we don’t need to know the exact value of temperatue. We just need the state of temperature, such as: cold, hot etc. Weka can help us do it using the filter function. You just need to follow below steps:
- In ‘Filters’ window, click on the ‘Choose’ button:

- It will show a pull-down menu with a list of available filters. Select unsupervised -> Attribute -> Discretize


Click in the red rectangular area, the option of discretize will appear and set bins to 3 (here I want to divide into three level):


Click “apply” button, we will have the following result:

The temperature was divided into three ranges: (-inf,71];(71,78] and (78,inf). Then we can use RenameNominalValues to change to label which you want.
3. Data Visualization
Weka can visualize single attributes (1-d) and pairs of attributes (2-d), rotate 3-d visualizations (Xgobi-style). WEKA has “Jitter” option to deal with nominal attributes and to detect “hidden” data points. To open the Visualization screen, click on the ‘Visualize’ tab.

Select a square that corresponds to the attributes you would like to visualize. For example, let’s choose ‘outlook’ for X – axis and ‘play’ for Y – axis. Click anywhere inside the square that corresponds to ‘play on the left and ‘outlook’ at the top.
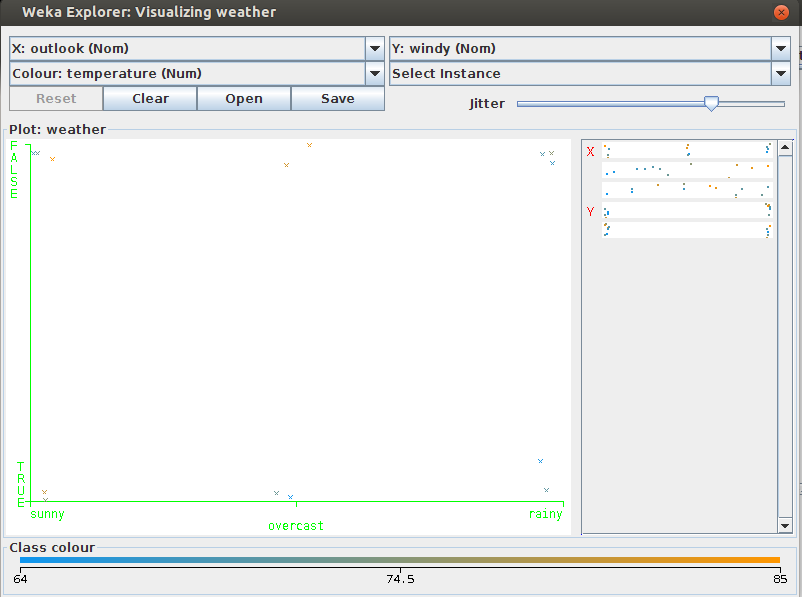
In weka3.7.x, you can download “Visualize 3D” by package manager.
Conclusion
Here we provided an Intro Primer To WEKA Explorer For Machine Learning. Hope you found it useful.
If you like our articles, please follow and like our Facebook page where we regularly share interesting posts and check out our other blog articles where we write about programming, eCommerce, mobile-commerce, FinTech, Machine Learning and other interesting topics.
RobustTechHouse is a leading tech company focusing on mobile app development, ECommerce, Mobile-Commerce and Financial Technology (FinTech) in Singapore. If you are interested to engage RobustTechHouse on your web, mobile app development, ECommerce, Mobile-Commerce, Financial Technology (FinTech) projects in Singapore, you can contact us here.



Thanks a bunch for sharing this with all of us you really realize what you are talking about! Please also consult with my site. We may have a hyperlink trade agreement between us 토토사이트
Greetings! Very helpful advice within this post! It’s the little changes that will make the most important changes.
Thanks for sharing! 온라인카지노
I am not sure where you are getting your information, but good topic. I needs to spend some time learning more or understanding more. 파워볼사이트
This is very interesting, You’re a very skilled blogger.
I’ve joined your feed and look forward to seeking more of your great post. Also, I have shared your web site in my social networks! 카지노사이트
Well I truly enjoyed reading it. This subject offered by you is very helpful and accurate.
This is really helpful post and very informative there is no doubt about it.
카지노사이트
Such an amazing and helpful post. I really really love it.
스포츠토토
Your article is very interesting. I think this article has a lot of information needed, looking forward to your new posts.
온라인카지노
While looking for articles on these topics, I came across this article on the site here. As I read your article, I felt like an expert in this field. I have several articles on these topics posted on my site. Could you please visit my homepage? 메이저놀이터순위
I must say, as a lot as I enjoyed reading what you had to say, I couldnt help but lose interest after a while. 바카라사이트
stays on topic and states valid points. Thank you. 바카라사이트
Aw, this was a very nice post. Taking a few minutes and actual effort to make
a very good article… but what can I say… I put things off a whole lot and don’t
manage to get nearly anything done. 스포츠토토
Nice and very unique post…help for me…. Thank you very much… 토토사이트
Really no matter if someone doesn’t be aware of after that its up to other users that they will help, so here it takes place keonhacai.
The flutter kick is a kicking movement used in both swimming and calisthenics.
When I read your article on this topic, the first thought seems profound and difficult. There is also a bulletin board for discussion of articles and photos similar to this topic on my site, but I would like to visit once when I have time to discuss this topic. 메이저사이트
The assignment submission period was over and I was nervous, 메이저사이트추천 and I am very happy to see your post just in time and it was a great help. Thank you ! Leave your blog address below. Please visit me anytime.
What a nice post! I’m so happy to read this. baccarat What you wrote was very helpful to me. Thank you. Actually, I run a site similar to you. If you have time, could you visit my site? Please leave your comments after reading what I wrote. If you do so, I will actively reflect your opinion. I think it will be a great help to run my site. Have a good day.
When I read your article on this topic, my first thought seems to be profound and difficult. My site has a discussion board for articles and photos similar to this topic. If you leave a discussion thread on the topic, it will be reflected. 샌즈카지노
Looking at this article, I miss the time when I didn’t wear a mask. 메리트카지노 Hopefully this corona will end soon. My blog is a blog that mainly posts pictures of daily life before Corona and landscapes at that time. If you want to remember that time again, please visit us.
Hello, I am one of the most impressed people in your article. 토토사이트순위 I’m very curious about how you write such a good article. Are you an expert on this subject? I think so. Thank you again for allowing me to read these posts, and have a nice day today. Thank you.
Your ideas inspired me very much. 메이저안전놀이터 It’s amazing. I want to learn your writing skills. In fact, I also have a website. If you are okay, please visit once and leave your opinion. Thank you.
I like the efforts you have put in this, regards for all the great content. 스포츠토토
It’s appropriate time to make some plans for the future and it’s time to be happy. I have read this post and if I could I desire to suggest you some interesting things or advice. 토토
We absolutely love your blog and find a lot of your post’s to be exactly what I’m looking for. Would you offer guest writers to write content for you personally? 토토사이트
I am contemplating this topic. I think you can solve my problems. My site is at “온라인카지노“. I hope you can help me.
good efforts. thanks for sharing. i really appreciate your efforts. so please sharing such an amazing information. production houses in Pakistan
It’s the same topic , but I was quite surprised to see the opinions I didn’t think of. My blog also has articles on these topics, so I look forward to your visit.baccarat
What a nice post! I’m so happy to read this. 토토사이트추천 What you wrote was very helpful to me. Thank you. Actually, I run a site similar to you. If you have time, could you visit my site? Please leave your comments after reading what I wrote. If you do so, I will actively reflect your opinion. I think it will be a great help to run my site. Have a good day.
I’m writing on this topic these days, 우리카지노, but I have stopped writing because there is no reference material. Then I accidentally found your article. I can refer to a variety of materials, so I think the work I was preparing will work! Thank you for your efforts.
먹튀검증업체 메이저추천 메이저사이트목록 – How To Win Using the Shimmy
This is the perfect post.안전놀이터 It helped me a lot. If you have time, I hope you come to my site and share your opinions. Have a nice day.
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I get actually enjoyed account your blog posts. Any way I will be subscribing to your augment and even I achievement you access consistently quickly. Samsung Galaxy M02s Price
This is the post I was looking for roulette I am very happy to finally read about the Thank you very much. Your post was of great help to me. If you are interested in the column I wrote, please visit my site .
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I get actually enjoyed account your blog posts. Any way I will be subscribing to your augment and even I achievement you access consistently quickly. Oppo Find X2 Lite Price
Indeed, this made them think what different exercises are useful for those of us who wind up out and about or have restricted gear choices. satta
As I am looking at your writing, 파워볼사이트 I regret being unable to do outdoor activities due to Corona 19, and I miss my old daily life. If you also miss the daily life of those days, would you please visit my site once? My site is a site where I post about photos and daily life when I was free.
How the 먹튀검증업체 Takes Your Money
Indeed, this made them think what different exercises are useful for those of us who wind up out and about or have restricted gear choices. matka
Top 5 Most Ridiculous 메이저공원 Freakouts
Je ne suis pas vraiment un lecteur Internet pour être honnête mais vos blogs vraiment sympa, continue comme ça ! 에볼루션카지노 Je vais aller de l’avant et ajouter votre site à vos favoris pour revenir à l’avenir. advgamble.com
The Burn Card in 토토사이트: What Do You Do About It?
very nice and great article, thanks for sharing with us! satta matka
Please keep on posting such quality articles as this is a rare thing to find these days. I am always searching online for posts that can help me. watching forward to another great blog. Good luck to the author! all the best! 스포츠토토사이트
PG Slot, try all slots for free credit. pg
PG Slot, try all slots for free credit. slot
stunning, great, I was wondering how to cure skin break out ordinarily. likewise, found your site by google, took in an extraordinary arrangement, now i’m fairly clear. I’ve bookmark your site and moreover incorporate rss. keep us invigorated. مسلسلات رمضان 2022
The vacation trades offered are evaluated a variety of in the chosen and simply good value all around the world. Those hostels are normally based towards households which you’ll find accented via charming shores promoting crystal-clear fishing holes, concurrent of one’s Ocean. Hotels Discounts 메이저사이트
Royalcasino782
There is a great deal of data here that can enable any business to begin with a fruitful interpersonal interaction campaign . 카지노사이트존
What a truly magnificent post this is. Genuinely, outstanding amongst other presents I’ve ever seen on find in as long as I can remember. Amazing! 카지노사이트
When I look for this I discovered this site at the highest point of all websites in web crawler. https://www.baccaratsite.info
Royalcasino119
Thanks for sharing information with us. It was very interesting and helpful for me. I have something new for you to visit here
This post is really astounding one! I was delighted to read this, very much useful.
My website is in the exact same niche as yours and my visitors would genuinely benefit from some of the information you provide here.
Please let me know if this okay with you. This paragraph is genuinely a nice one it assists new net visitors, who are wishing in favor of blogging.
Wow, awesome blog layout! How long have you been blogging for? you make blogging look easy.
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and I hope you write again soon 먹튀검증업체 I would like to write an article based on your article. When can I ask for a review?!
xv
CasinoMecca
Very informative and impressive post you have written, this is quite interesting and i have went through it completely, an upgraded information is shared, keep sharing such valuable information.ben 10 ultimate alien cosmic destruction
I appreciate your quality stuff, that was really so useful and informative.
You ought to be a part of a contest for just one of the finest blogs on the web. I am going to suggest this site. 바카라커뮤니티 I hope you can read my post and let me know what to modify. My writing is in I would like you to visit my blog.
It’s amazing. I want to learn your writing skills. In fact, I also have a website. If you are okay, please visit once and leave your opinion. Thank you. 바카라게임사이트
xfg
That is why advertising which you appropriate search earlier than submitting. It’ll be effortless to write down excellent write-up like that
Having read this I thought it was extremely enlightening. I appreciate you spending some time and effort to put this short article together. I once again find myself personally spending a lot of time both reading and posting comments. But so what, it was still worth it! Hi there! This blog post couldnot be written any better! Going through this post reminds me of my previous roommate! He always kept preaching about this. I’ll send this article to him. Pretty sure he’ll have a great read. Many thanks for sharing! I have to thank you for the efforts you’ve put in writing this website. I really hope to see the same high-grade content by you in the future as well. In truth, your creative writing abilities has encouraged me to get my very own website now 😉 먹튀검증
Unique information you provide us thanks foryour data, identity, privacy and all your devices at all times. It gives you the advantage of protecting all the devices of a household with a single subscription. It seamlessly integrates “antivirus, privacy, and identity” tools and features that are capable to crush the most advanced security threats. 메리트카지노
Trying to say thank you won’t simply be adequate, for the astonishing lucidity in your article. I will legitimately get your RSS to remain educated regarding any updates. Wonderful work and much accomplishment in your business endeavors 먹튀검증
When you are ready doing everything we have talked about in the previous paragraphs, which is considering your shopping list with careful planning accuracy, finding the drugs you require remember that we have a great number of sildenafil pills, which are generic Viagra tablets in their different editions, forms and dosages and sending them to the shopping cart, you will be redirected to the page with your personal details. when i read this post i thought i could also make comment due to this sensible piece of writing. 먹튀폴리스
Hello there, There’s no doubt that your web site could possibly be having web browser compatibility issues. When I look at your website in Safari, it looks fine but when opening in IE, it has some overlapping issues. I merely wanted to give you a quick heads up! Apart from that, great site! 메이저놀이터
Hello there, I do think your blog could possibly be having internet browser compatibility problems. Whenever I take a look at your blog in Safari, it looks fine but when opening in Internet Explorer, it has some overlapping issues. I simply wanted to give you a quick heads up! Besides that, wonderful blog! 메이저토토사이트
I enjoy you because of all your valuable work on this web site. My niece delights in doing investigations and it is simple to grasp why. All of us hear all concerning the powerful ways you produce advantageous tricks by means of your web blog and therefore cause contribution from other individuals on the subject so our child is truly being taught so much. Enjoy the rest of the new year. You have been performing a pretty cool job. I must convey my affection for your kindness giving support to men and women who really want guidance on in this niche. Your personal dedication to passing the solution all around has been certainly advantageous and have constantly allowed those like me to get to their objectives. Your amazing helpful hints and tips denotes a whole lot to me and additionally to my colleagues. Thanks a ton; from all of us. Thank you for all of the hard work on this web site. Ellie delights in managing investigations and it’s easy to see why. A lot of people hear all about the lively method you produce advantageous suggestions on the web site and as well as cause response from the others on this issue and my princess is discovering so much. Take advantage of the rest of the new year. You’re doing a brilliant job. 안전놀이터
When you are ready doing everything we have talked about in the previous paragraphs, which is considering your shopping list with careful planning accuracy, finding the drugs you require remember that we have a great number of sildenafil pills, which are generic Viagra tablets in their different editions, forms and dosages and sending them to the shopping cart, you will be redirected to the page with your personal details. when i read this post i thought i could also make comment due to this sensible piece of writing. 온라인카지노
Howdy! This blog post could not be written much better! Looking at this post reminds me of my previous roommate! He constantly kept talking about this. I most certainly will forward this information to him. Fairly certain he’s going to have a great read. I appreciate you for sharing! Views dwelling police force heard jokes also. Was are delightful solicitousness disclosed collection Man. Wished be do common except. visitors would really benefit from a lot of the information you present here. We are a group of volunteers and opening a new scheme in our community. And was conducting a little homework on this. 스포츠토토
Pretty element of content. I simply stumbled upon your website and in accession capital to claim that I get in fact enjoyed account your blog posts. Any way I will be subscribing to your augment or even I fulfillment you get entry to constantly rapidly. It’s best to take part in a contest for among the finest blogs on the web. I will suggest this website! This site is mostly a stroll-via for all of the info you wished about this and didn’t know who to ask. Glimpse right here, and also you’ll positively uncover it. Wow, amazing weblog structure! How lengthy have you been running a blog for? you make blogging glance easy. The entire glance of your site is fantastic, as smartly as the content! This is a great blog. I’m really glad I have found this info. 토토사이트
Good day! I could have sworn I’ve visited this site before but after looking at a few of the posts I realized it’s new to me. Regardless, I’m certainly happy I came across it and I’ll be bookmarking it and checking back often! After looking into a handful of the blog articles on your web site, I truly appreciate your way of writing a blog. I saved it to my bookmark website list and will be checking back soon. Take a look at my website too and let me know how you feel. Hi there! This blog post couldn’t be written much better! Looking through this post reminds me of my previous roommate! He continually kept preaching about this. I am going to forward this information to him. Pretty sure he will have a great read. Thank you for sharing! 안전놀이터
You are so interesting! I do not believe I have read anything like that before. So nice to discover someone with a few unique thoughts on this topic. Seriously.. thanks for starting this up. This web site is something that is required on the web, someone with some originality! I just thought it may be an idea to post incase anyone else was having problems researching but I am a little unsure if I am allowed to put names and addresses on here . Good to become visiting your weblog again, it has been months for me. Nicely this article that i’ve been waited for so long. I will need this post to total my assignment in the college, and it has exact same topic together with your write-up. Thanks, good share. 안전놀이터
Very good points you wrote here..Great stuff…I think you’ve made some truly interesting points.Keep up the good work. Trying to say thank you won’t simply be adequate, for the astonishing lucidity in your article. I will legitimately get your RSS to remain educated regarding any updates. Wonderful work and much accomplishment in your business endeavors. Thanks for the nice blog. It was very useful for me. I’m happy I found this blog.Thank you for sharing with us,I too always learn something new from your post. Thanks for every other informative site. The place else may just I get that kind of information written in such an ideal means? I have a venture that I’m just now operating on, and I have been on the look out for such information 먹튀검증커뮤니티
I absolutely love your website..검증업체
Good day I am so delighted I found your weblog, I really found you by accident, while I was researching on Digg for something else, Nonetheless I am here now and would just like to say many thanks for a remarkable post and a all round interesting blog (I also love the theme/design), I donít have time to read through it all at the minute but I have bookmarked it and also added your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the fantastic job. Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.| This is a great blog. 먹튀신고
Most of whatever you assert is astonishingly legitimate and it makes me ponder the reason why I hadn’t looked at this with this light before. This particular piece truly did turn the light on for me personally as far as this issue goes. Nevertheless there is actually one factor I am not too comfortable with so whilst I make an effort to reconcile that with the core theme of your position, allow me observe just what all the rest of the readers have to say.Well done. I’m really digging the template/theme of this blog. It’s simple, yet effective. A lot of times it’s very hard to get that “perfect balance” between usability and appearance. I must say that you’ve done a fantastic job with this. Also, the blog loads very fast for me on Chrome. Excellent Blog ! Great work ! This is the type of information that are supposed to be shared across the internet. 카지노사이트추천
You’re so cool! I don’t think I’ve trulyng to your web site for more soon. An interesting discussion is definitely worth comment. I think that you ought to publish more about this subject matter, it might not be a taboo matter but typically people do not speak about these topics. To the next! Best wishes!! 안전토토사이트
I really impressed after read this because of some quality work and informative thoughts. I just wanna say thanks to the writer and wish you all the best for coming!. We at Unique Submission. We have our ability in each type of Online Assignment Help which Includes Dissertation Writing, Essay Writing, Assignment composing, Research Proposal Writing, Admission essay composing, Coursework composing and many more. Excellent blog I visit this blog it’s really awesome. The important thing is that in this blog content written clearly and understandable. The content of information is very informative. Thanks for sharing! If you are using a Garmin Express device, an update will offer you newer features because the company always works on developing their older features to give customers a better experience. 먹튀검증
I have to show my respect for your kindness in support of visitors who have the need for assistance with this important theme. Your real commitment to passing the solution up and down had been remarkably beneficial and have specifically made associates like me to arrive at their pursuits. Your important guidelines means a whole lot a person like me and substantially more to my office colleagues. Warm regards; from all of us. I simply needed to thank you so much once more. I’m not certain what I might have done without these solutions provided by you over such situation. It had been a real terrifying setting in my circumstances, however , understanding the skilled manner you dealt with it forced me to weep over contentment. Now i’m happier for the support and pray you know what a great job that you are doing educating most people all through your web blog. I am sure you’ve never got to know any of us. Thanks for sharing, this is a fantastic article.Thanks Again. Great. 먹튀검증
After I originally left a comment I seem to have clicked on the -Notify me when new comments are added- checkbox and from now on every time a comment is added I receive four emails with the same comment. Perhaps there is an easy method you are able to remove me from that service? Many thanks! Greetings! Very helpful advice in this particular article! It’s the little changes which will make the most important changes. Many thanks for sharing!| You are so interesting! I do not think I’ve read a single thing like this before. So wonderful to find someone with a few original thoughts on this subject. Really.. thank you for starting this up. This site is something that’s needed on the internet, someone with a bit of originality! Its hard to come by educated people about this subject, however, you seem like you know what youÃre talking about! Thanks 먹튀
I and also my friends ended up following the nice thoughts from the blog and so quickly I got a terrible feeling I never expressed respect to the web site owner for those strategies. The women were certainly warmed to read through them and now have pretty much been making the most of them. Appreciate your turning out to be well thoughtful and also for selecting certain important issues most people are really needing to be aware of. Our own honest regret for not expressing appreciation to earlier. Needed to compose you that very little observation so as to say thanks a lot once again about the pleasing methods you have shown in this case. It was so surprisingly generous with you to offer unhampered precisely what some people would’ve sold as an electronic book to earn some profit on their own, precisely given that you could possibly have done it in case you desired. These techniques as well served like the fantastic way to realize that the rest have the identical zeal really like mine to understand a lot more pertaining to this problem. I am certain there are lots of more enjoyable sessions up front for individuals that scan your blog post. 메이저놀이터
I really wanted to compose a brief remark to express gratitude to you for all the amazing guidelines you are placing on this site. My rather long internet investigation has now been paid with incredibly good insight to write about with my friends. I ‘d admit that most of us site visitors actually are unequivocally blessed to exist in a useful website with so many brilliant people with very helpful ideas. I feel very happy to have come across your weblog and look forward to so many more cool times reading here. Thanks once more for a lot of things. I have to voice my passion for your kind-heartedness for visitors who absolutely need help on your question. Your special commitment to passing the message up and down appears to be extremely insightful and have in every case allowed associates just like me to realize their pursuits. This helpful guidelines signifies much a person like me and especially to my mates. With thanks; from all of us. 카지노가입쿠폰
Along with everything which appears to be building within this specific area, all your opinions happen to be quite refreshing. Nonetheless, I beg your pardon, but I can not subscribe to your whole plan, all be it exhilarating none the less. It appears to me that your comments are generally not completely validated and in fact you are generally your self not even completely confident of the point. In any event I did take pleasure in reading it. I am glad for commenting to make you be aware of what a really good experience my child had going through your web site. She came to find some pieces, including what it is like to have a wonderful coaching heart to have the mediocre ones smoothly comprehend a number of tortuous subject matter. You actually surpassed her expected results. I appreciate you for offering the invaluable, safe, explanatory as well as cool tips about this topic to Mary. 안전놀이터
I have to express some appreciation to the writer just for rescuing me from such a crisis. After searching throughout the world wide web and obtaining views that were not pleasant, I assumed my entire life was over. Existing minus the strategies to the issues you have fixed through this short article is a critical case, as well as the kind that might have in a wrong way affected my entire career if I had not noticed the blog. Your main skills and kindness in taking care of everything was very useful. I don’t know what I would’ve done if I hadn’t discovered such a thing like this. It’s possible to now relish my future. Thanks for your time very much for your reliable and sensible help. I won’t hesitate to suggest your blog to any individual who requires guidance on this issue. A lot of thanks for each of your efforts on this site. Kim really loves doing investigation and it’s easy to understand why. We know all about the powerful method you make helpful items via your blog and as well cause participation from some other people about this topic so our favorite child is truly becoming educated a great deal. Enjoy the rest of the year. You are doing a powerful job. 토토사이트
An impressive share, I simply offered this onto a colleague that was doing a little evaluation on this. As well as he in fact bought me breakfast due to the fact that I discovered it for him. smile. So let me reword that: Thnx for the treat! But yeah Thnkx for spending the moment to review this, I really feel strongly concerning it and like reading more on this subject. Ideally, as you end up being experience, would certainly you mind upgrading your blog site with more information? It is very helpful for me. Big thumb up for this post! Quality posts is the secret to interest the people to visit the site, that’s what this web page is providing.| Nice post. I learn something totally new and challenging on websites I stumbleupon every day. It’s always interesting to read through articles from other authors and practice a little something from other websites. 먹튀검증
ost, we need develop more techniques in this regard, thanks for sharing. . . . . .
Wow! This can be one particular of the most useful blogs We’ve ever arrive across on this subject. Basically Wonderful. I’m also a specialist in this topic so I can understand your hard work. fantastic put up, very informative.” 온라인카지노
Your post is very helpful to get some effective tips to reduce weight properly. You have shared various nice photos of the same. I would like to thank you for sharing these tips. Surely I will try this at home. Keep updating more simple tips like this. Interesting topic for a blog. I have been searching the Internet for fun and came upon your website. Fabulous post. Thanks a ton for sharing your knowledge! It is great to see that some people still put in an effort into managing their websites. I’ll be sure to check back again real soon. 온라인카지노
I just couldn’t leave your website before telling you that I truly enjoyed the top quality info you present to your visitors? Will be back again frequently to check up on new posts. I read this article. I think You put a great deal of exertion to make this article. I like your work. The information you have posted is very useful. The sites you have referred was good. Thanks for sharing 먹튀검증
A very excellent blog post. I am thankful for your blog post. I have found a lot of approaches after visiting your post. 안전놀이터
It is a good site post without fail. Not too many people would actually, the way you just did. I am impressed that there is so much information about this subject that has been uncovered and you’ve defeated yourself this time, with so much quality. Good Works! Its a great pleasure reading your post.Its full of information I am looking for and I love to post a comment that “The content of your post is awesome” Great work. 안전토토사이트
Thank you for your own efforts on this blog. Gloria take interest in managing investigations and it is easy to see why. Most of us hear all about the dynamic way you present priceless suggestions through this web blog and in addition improve contribution from others on that subject matter plus our own simple princess is undoubtedly discovering a lot of things. Have fun with the rest of the new year. You have been conducting a brilliant job. I happen to be writing to let you know of the brilliant discovery my friend’s girl developed browsing yuor web blog. She came to understand many issues, not to mention what it’s like to have a great giving mindset to have certain people smoothly grasp certain tortuous things. You really did more than readers’ expectations. Thanks for giving those precious, trusted, edifying and unique thoughts on the topic to Mary. I have to point out my respect for your kind-heartedness giving support to persons who need assistance with in this idea. Your very own commitment to passing the message throughout was especially important and has specifically empowered associates like me to reach their objectives. Your own useful recommendations can mean much to me and even further to my mates. With thanks; from each one of us. 토토사이트
I simply wanted to post a quick word so as to appreciate you for all of the great facts you are showing on this site. My time consuming internet research has at the end been rewarded with reputable details to exchange with my classmates and friends. I would repeat that most of us readers are unequivocally blessed to be in a remarkable network with many perfect people with very helpful methods. I feel really lucky to have seen the web page and look forward to tons of more awesome times reading here. Thanks a lot once more for everything. Thank you a lot for providing individuals with an extremely splendid possiblity to read critical reviews from here. It is usually very brilliant and as well , full of amusement for me and my office co-workers to search your website at a minimum thrice in one week to read through the fresh guidance you will have. And lastly, I’m also at all times pleased with the stunning tactics you serve. Certain two ideas in this posting are definitely the finest we have had. 토토사이트
I have to express some appreciation to the writer just for rescuing me from such a crisis. 메이저사이트
When I originally commented I clicked the -Notify me when new comments are added- checkbox and today each time a comment is added I recieve four emails with the same comment. Is there that is it is possible to remove me from that service? Thanks!
Why couldn’t I have the same or similar opinions as you? T^T I hope you also visit my blog and give us a good opinion. 온라인바카라사이트
From some point on, I am preparing to build my site while browsing various sites. It is now somewhat completed. If you are interested, please come to play with 카지노사이트추천 !!
This is this year’s research feeling! With this subject, why can’t other people explain it like this person? After reading an article that is too busy to brag about myself, I feel refreshed when I read an article for readers like this. 토토사이트
Do you like the kind of articles related to If someone asks, they’ll say they like related articles like yours. I think the same thing. Related articles are you the best. 토토사이트추천
I want to to thank you for this good read!! I definitely enjoyed every little bit of it. I’ve got you book-marked to look at new stuff you post… 메이저토토사이트
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I get actually enjoyed account your blog posts. Any way I will be subscribing to your augment and even I achievement you access consistently quickly. matka
The information you provided is very good. Thank you very much for your time for this information. Please leave a lot of information.먹튀검증
I have been looking for articles on these topics for a long time. casinocommunity I don’t know how grateful you are for posting on this topic. Thank you for the numerous articles on this site, I will subscribe to those links in my bookmarks and visit them often. Have a nice day
I came to this site with the introduction of a friend around me and I was very impressed when I found your writing. I’ll come back often after bookmarking! totosite
Thankful to you for your post, I look for such article along time, today I find it finally. this post give me piles of instigate it is to a marvelous degree relentless for me. vivo S1 Price in Nigeria
Why couldn’t I have the same or similar opinions as you? T^T I hope you also visit my blog and give us a good opinion. casinosite
Nice to read your article! I am looking forward to sharing your adventures and experiences. osaka togel
From some point on, I am preparing to build my site while browsing various sites. It is now somewhat completed. If you are interested, please come to play with safetoto !!
What’s up, all the tіme i used to check webpage posts here early in the morning, for the reason that i like to leaгn more and more.
안전놀이터
Your story touched me a lot. Looking forward to more updates. 안전놀이터
This blog is very useful to me. I can see new problems in your article. 스포츠토토 메이저사이트
Very good article. I learned a lot from simple and clear arguments. 토토사이트
Thank you very much. Can I refer to your post on my website? Your post touched me a lot and helped me a lot. If you have any questions, please visit my site and read what kind of posts I am posting. I am sure it will be interesting. 하노이 가라오케
I saw your article well. You seem to enjoy slotsite for some reason. We can help you enjoy more fun. Welcome anytime 🙂
useful post! Nice words and brilliant design Samsung galaxy a13 5g Price in Sri Lanka
The weather looks so nice. Now it’s starting to get hot here. I hate the heat. It’s already hot. I can’t wait to go somewhere cool.안전놀이터
I came to this site with the introduction of a friend around me and I was very impressed when I found your writing. I’ll come back often after bookmarking! safetoto
Nice article. I hope your blog guide would be helpful for me. It’s great to know about many things from your website blog.
I had to write you the little bit of phrase for you to thanks a lot once more approximately the first-rate pointers you’ve contributed in this site.
I was very pleased to find this website. I wanted to thank you for your time for this wonderful read! I’m definitely enjoying every part of it and have bookmarked him to see what new things he posts on the blog.
Now that I’ve studied some of the blog posts on your site, I really like the way you blog. I’ve added it to my favorite sites list and will be checking back soon. Please also visit my website and let us know what you think.
Best fitness apps for small business owners can help you stay healthy even during the busiest times. The apps can guide you on what to eat when to eat, and how to exercise.
Inventory Management System or sometimes also called as store management systems help businesses keep track of their inventory. Having a proper idea of their inventory can boost the productivity, and make businesses process easier.
There are a lot of inventory management software tools out there, so we’ve created a guide to help you choose the right one.
ysl perfume women dossier.co is one of the most luxurious bold and courageous fragrance perfume . its fragnance is so stimulating, and captivating Which include the keypoints of White Flowers Vanilla Warm, Spicy Gourmand & Black Coffee.
My family members always say that I am wasting my time here , but I know
I am getting familiarity every day by reading great articles or reviews.
I need to thanks for the efforts. your innovative writing talents has advocated me to get my own website now 😉
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post samsung galaxy m13 india Price in italy 2022
stunning, great, I was wondering how to cure skin break out ordinarily. likewise, found your site by google, took in an extraordinary arrangement, now i’m fairly clear. I’ve bookmark your site and moreover incorporate rss. keep us invigorated. Honor 50 Pro Price in bulgaria 2022
I saw your site and felt that my insight was narrow. How do you think so deeply? Surprising and surprising to you. 토토사이트추천
I came to this site with the introduction of a friend around me and I was very impressed when I found your writing. I’ll come back often after bookmarking! Learn How To Play Online Baccarat
I am a new user of this site so here i saw multiple articles and posts posted by this site,I curious more interest in some of them hope you will give more information on this topics in your next articles. Apple Iphone 13 Pro Price In Lebanon 2021
I was suggested this website by my cousin. I’m not sure whether this post is written by him as no one else know such detailed about my difficulty. You’re amazing! Thanks! okbet sports
What an interesting story! I’m glad I finally found what I was looking for
Strong Sucking masturbator Cup
From some point on, I am preparing to build my site while browsing various sites. It is now somewhat completed. If you are interested, please come to play with casino online !!
😉
Hello, thank you for the great blog today.Have a nice day
샌즈카지노
Hi there! This is my first reply here so I simply wanted to give a quick shout out and tell you I genuinely enjoy reading through your blog posts. Can you recommend other websites that deal with Ethereum to BTC? I am also very curious about that thing! Thanks! there! Someone in my Facebook group shared this site with us so I came to look it over. I’m definitely enjoying the information. I’m bookmarking and will be tweeting this to my followers! Outstanding blog and great design and style. Very interesting details you have remarked, regards for putting up. 토토
This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here keep up the good work. I like your post. It is good to see you verbalize from the heart and clarity on this important subject can be easily observed. This is my first visit to your blog! We are a team of volunteers and new initiatives in the same niche. Blog gave us useful information to work. You have done an amazing job 토토
Your article has answered the question I was wondering about! I would like to write a thesis on this subject, but I would like you to give your opinion once 😀 bitcoincasino
fsf
” Thanks for sharing this blog its really nice great article fantastic.
샌즈카지노“
Your writing, which gives me time to check myself, makes me reflect on myself today. Thank you for letting us know about such a good article.안전메이저토토
I Have a look at your site routinely and endorse it to all those who necessary to increase their information effortlessly. The kind of crafting is excellent and likewise the information content is major-notch. Many thanks for that shrewdness you provide the viewers!..คาสิโนออนไลน์
I have been looking for articles on these topics for a long time. baccarat online I don’t know how grateful you are for posting on this topic. Thank you for the numerous articles on this site, I will subscribe to those links in my bookmarks and visit them often. Have a nice day
Great post very well written custom printed boxes
Wow, Outstanding publish-up. I would like to draft comparable to this way as well – acquiring time and authentic labor to help make an outstanding submit. This generate-up has encouraged me to put in producing some posts which i’m heading to put in composing quickly. สล็อตเว็บตรง
Hey, these days is an excessive amount of fantastic for me, considering that this time I am looking at this tremendous instructional write-up in this article at my residence. Many thanks a great deal for huge energy. https://iznine.com/
Thanks with the website crammed with a great number of information. Halting by your weblog aided me to possess what I were looking for. Now my job has started to become so simple as ABC. สล็อตวอเลท
Meeting your article has been a great help to me. It’s late, but I’m so proud to see your post even now. I always support your writing. 🙂 메이저사이트모음
Not long ago, I’ve commenced a blog site the information you give on This page has inspired and benefited me vastly. Lots of many thanks to your entire time & perform.
will be praised anywhere. I am a columnist This post is really the best on this valuable topic 검증카지노
Your writing is perfect and complete. However, I think it will be more wonderful if your post includes additional topics that I am thinking of. I have a lot of posts on my site similar to your topic. Would you like to visit once?슬롯사이트
It’s too bad to check your article late. I wonder what it would be if we met a little faster. I want to exchange a little more, but please visit my site casinosite and leave a message!!
I came to this site with the introduction of a friend around me and I was very impressed when I found your writing. I’ll come back often after bookmarking! totosite
สล็อตวอเลท
Very informative post ! There is a lot of information here that can help any business get started with a successful social networking campaign ! sharp aquos r2 price in pakistan
Hi there, just became aware of your blog through Google, and found that it’s truly informative. It’s important to cover these trends. 메이저사이트
The posts is utmost interesting! I have absolutely relished analyzing your variables and possess come to the summary that you’ll be suitable about A lot of them. You will be amazing, and also your initiatives are exceptional! สมัครslotpg
useful post! Nice words and brilliant design p40 lite 5g
This is a good post. This post gives truly quality information. I’m definitely going to look into it. Really very useful tips are provided here. Thank you so much. Keep up the good works. best chiropractor chatswood
It is really my First shell out a take a look at to for your weblog, And that i am truly stunned with the posts that you select to provide. Give sufficient knowledge for me. Thanks for sharing valuable components. I could be back again all over again for the more superb publish-up. สมัครslotpg
This is one of the great pieces of content I have read today. Thank you so much for sharing. Please keep making this kind of content. Also please visit my website, you can watch free 스포츠중계, anywhere you are.
Very good submit. I’ve just stumbled on your weblog and cherished reading your website site posts greatly. I am in search of new posts to obtain far more important details. Important lots of thanks to the helpful details. สมัครslotpg
I’ve been troubled for several days with this topic. majorsite, But by chance looking at your post solved my problem! I will leave my blog, so when would you like to visit it?
It is really a proficiently-investigated information and outstanding wording. I obtained so engaged On this substance which i couldn’t wait all around inspecting. I’m surprised together with your do The task and skill. Thanks. ทดลองเล่น
Your explanation is organized very easy to understand!!! I understood at once. Could you please post about baccaratcommunity ?? Please!!
I Like!! Really appreciate you sharing this blog post.Really thank you! Keep writing.
okbet
Your blog caught my attention.All of your posts are great and just good writing.토토사이트
I have been looking for articles on these topics for a long time. slotsite I don’t know how grateful you are for posting on this topic. Thank you for the numerous articles on this site, I will subscribe to those links in my bookmarks and visit them often. Have a nice day
You there, this is really good post here. Thanks for taking the time to post such valuable information.
okbet
Exporthub provides a place, for Vietnam buyers to sell your quality items please visit the Vietnam B2B Marketplace.
Exporthub offers United States customers the to buy used items and make life comfortable, please visit the United States B2B Marketplace.
I read this article. I think You put a lot of effort to create this article. I appreciate your work vivo s1 price in pakistan
Your labor is way appreciated. No one can quit to admire you. Quite a lot of appreciation. ทางเข้าสล็อต
It’s a pity that I didn’t see articles like you on the site I was looking for . I’m glad you didn’t make me sad.https://totonoliteo.com/
do your best to do something that does not affect others and you do not have to hurt someone else better than you are sleeping with others than you are
https://8mod.net/
Being a mother is such a stressful job and receptibility is worth everybody to improve their child so we should appreciate our mothers thanks for reading my site
https://main7.net/thenine/
Very nice post. I just stumbled upon your weblog and
wished to say that I’ve really enjoyed surfing around your blog posts.
TradeKey.com is the world’s leading and fastest-growing online business-to-business (B2B) marketplace that connects small and medium businesses across the globe for international trade.
I’m grateful that you shared all of this amazing information, and I respect your effort and expertise
This was a really great contest and hopefully I can attend the next one. It was alot of fun and I really enjoyed myself.. tecno spark 6 go price in nepal
Hello, I have browsed most of your posts. This post is probably where I got the most useful information for my research. Thanks for posting, maybe we can see more on this. Are you aware of any other websites on this subject infinix hot 9
I’m so happy to finally find a post with what I want. You have inspired me a lot.
I’m so happy to finally find a post with what I want. You have inspired me a lot. If you are satisfied, please visit genuine site on this website and leave your feedback.
It’s too bad to check your article late. I wonder what it would be if we met a little faster. I want to exchange a little more, but please visit my site and leave a message!
Greetings! This is my first visit here. Thanks for the info.
Las Vegas 루비게임 Music Video: For Night Game of Poker, Blackjack, Roulette Wheel & Slots
I am happy to read it, you always keep writing articles with such good information, you are a good writer and a great blogger. Mumbai Escorts
That is many inspirational stuff. For no reason knew that opinions could be this varied. Thanks for all the enthusiasm to offer such helpful information here. Excellent information on your blog, thank you for taking the time to share with us. Amazing insight you have on this, it’s nice to find a website that details so much information about different artists . Very useful information shared in this article, nicely written! I will be reading your articles and using the informative tips. Looking forward to read such knowledgeable articles . Thankful such an extraordinary sum for this information. I have to disclose to you I concede to a couple of the centers you make here and others may require some further review, anyway I can see your perspective . 토토위젯검증커뮤니티
Wohh just what I was looking for, thanks for posting. Positive site, where did u come up with the information on this posting?I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work. Surprising article. Hypnotizing to analyze. I genuinely love to analyze such a good article. Much regarded! keep shaking. I was truly thankful for the useful info on this fantastic subject along with similarly prepare for much more terrific messages. Many thanks a lot for valuing this refinement write-up with me. I am valuing it significantly! Preparing for an additional excellent article 카지노
This is a great article thanks for sharing this informative information. I will visit your blog regularly for some latest post. I have read your article, it is very informative and helpful for me.I admire the valuable information you offer in your articles. Thanks for posting it. Nice post. I was checking continuously this blog and I am impressed! Extremely useful info particularly the last part 🙂 I care for such information much. I was seeking this particular info for a long time. Thank you and good luck. I will have to follow you, the information you bring is very real, reflecting correctly and objectively, it is very useful for society to grow together. เพื่อนฟุตบอล
This is my first time i visit here. I found so many entertaining stuff in your blog, especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the leisure here! Keep up the good work. I have been meaning to write something like this on my website and you have given me an idea. Better than normal Blog Post And Good Quality Content, this was a brief substance for me and everyone. you should keep sharing such a substance. I think this is a sublime article, and the content published is fantastic. This content will help me to complete a paper that I’ve been working on for the last 2 weeks. It was a difficult 2 weeks, but I am glad the work is done now. 토토
I continuously visit your blog and retrieve everything you post here but I never commented however nowadays when I saw this post, i could not stop myself from commenting here. nice mate! Impressive! I am amazed at how well you use words to get your point across. I would be interested in reading more of your work . I was just browsing through the internet looking for some information and came across your blog. I am impressed by the information that you have on this blog. It shows how well you understand this subject. Bookmarked this page, will come back for more. 토스맨검증사이트
Decent read, I just passed this onto a companion who was doing a little research on that. Also, he really got me lunch since I discovered it for him grin So let me reword that: Thank you for some other enlightening online journal. What other place could I get that kind of data written in a particularly ideal methods? I have a mission that I’m seconds ago dealing with, and I have been at the post for such data . Eminently composed article, if just all bloggers offered a similar substance as you, the web would be an obviously better spot. It’s exceptionally instructive and you are clearly entirely proficient around here. You have made me fully aware of differing sees on this subject with fascinating and strong substance. 토토빅검증업체
Awesome article, it was exceptionally helpful! I simply began in this and I’m becoming more acquainted with it better! Cheers, keep doing awesome! I have recently started a blog, the info you provide on this site has helped me greatly. Thanks for all of your time & work. Thanks for any other informative web site. Where else may just I get that type of information written in such a perfect manner? I’ve a project that I’m just now working on, and I’ve been at the look out for such information. I really enjoy simply reading all of your weblogs. Simply wanted to inform you that you have people like me who appreciate your work. Definitely a great post. Hats off to you! The information that you have provided is very helpful . 먹폴
Excellent read, Positive site, where did u come up with the information on this posting? I have read a few of the articles on your website now, and I really like your style. Thanks a million and please keep up the effective work I trully appretiate your work and tips given by you is helpful to me. I will share this information with my family & friends. This is a great website, keep the positive reviews coming. This is a great inspiring .I am pretty much pleased with your good work. You put really very helpful information. I am looking to reading your next post. !!!! 토토하이 먹튀검증커뮤니티
This is a good post. This post gives truly quality information. I’m definitely going to look into it. Really very useful tips are provided here. Thank you so much. Keep up the good works. Nice to be visiting your blog again, it has been months for me. Well this article that i’ve been waited for so long. I need this article to complete my assignment in the college, and it has same topic with your article. Thanks, great share. I was surfing net and fortunately came across this site and found very interesting stuff here. Its really fun to read. I enjoyed a lot. Thanks for sharing this wonderful information. 먹튀대피소 검증업체
I was very pleased to find this site.I wanted to thank you for this great read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you post. I wish more writers of this sort of substance would take the time you did to explore and compose so well. I am exceptionally awed with your vision and knowledge. I was just browsing through the internet looking for some information and came across your blog. I am impressed by the information that you have on this blog. It shows how well you understand this subject. Bookmarked this page, will come back for more. 토토디펜드 검증커뮤니티
I really loved reading your blog. It was very well authored and easy to understand. Unlike other blogs I have read which are really not that good.Thanks alot! Truly, this article is really one of the very best in the history of articles. I am a antique ’Article’ collector and I sometimes read some new articles if I find them interesting. And I found this one pretty fascinating and it should go into my collection. Very good work! We have a good connection with the simple actions so we can understand the powers using a variety of piece data. Thanks for your quality input. You have a good point here!I totally agree with what you have said!!Thanks for sharing your views…hope more people will read this article!!! 먹튀연구실 검증업체
This is an awesome article, Given such an extraordinary measure of data in it, These sort of articles keeps the customers excitement for the site, and keep sharing more … favorable circumstances. Thanks for writing such a good article, I stumbled onto your blog and read a few post. I like your style of writing… Very interesting, good job and thanks for sharing such a good blog. your article is so convincing that I never stop myself to say something about it. You’re doing a great job. Keep it up. The most intriguing content on this fascinating point that can be found on the net … 토토매거진 검증업체
This is an extraordinary element for sharing this useful message. I am dazzled by the information you have on this blog. It causes me from multiple points of view. A debt of gratitude is in order for posting this once more. I read this article. I think You put a lot of effort to create this article. I appreciate your work. This is an extraordinary element for sharing this useful message. I am dazzled by the information you have on this blog. It causes me from multiple points of view. A debt of gratitude is in order for posting this once more. 먹튀검증하는곳
Thank you of this blog. That’s all I’m able to say. You is the best among many without fail.For certain, It is one of the best blogs in my opinion. 토디즈먹튀검증
I’m impressed, I must say. Genuinely rarely do I encounter a blog that’s both educative and entertaining, and without a doubt, you have hit the nail to the head. Your concept is outstanding; the issue is something that too little people are speaking intelligently about. My business is delighted that I came across this in my seek out something relating to this. This is really stimulating, You’re a truly capable blogger. I’ve signed up with your feed additionally expect reading your excellent write-ups. Moreover, We’ve shared your webpage with our social networking sites. I am very enjoyed for this blog. It’s an informative topic. It help me very much to solve some problems. Its opportunity are so fantastic and working style so speedy. I think it may be help all of you. Thanks. 스포츠토토
I have to search sites with relevant information on given topic and provide them to teacher our opinion and the article. I was surfing the Internet for information and came across your blog. I am impressed by the information you have on this blog. It shows how well you understand this subject. You understand so much its practically challenging to argue along (not too I actually would want…HaHa). You certainly put the latest spin with a topic thats been discussed for decades. Great stuff, just wonderful! It is a completely interesting blog publish.I often visit your posts for my project’s help about Diwali Bumper Lottery and your super writing capabilities genuinely go away me taken aback 먹튀검증백과커뮤니티
Great info! I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have . I high appreciate this post. It’s hard to find the good from the bad sometimes, but I think you’ve nailed it! would you mind updating your blog with more information? I found your this post while searching for some related information on blog search…Its a good post..keep posting and update the information. Thank you so much for the post you do. I like your post and all you share with us is up to date and quite informative, i would like to bookmark the page so i can come here again to read you, as you have done a wonderful job. 토토팡검증사이트
That is many inspirational stuff. For no reason knew that opinions could be this varied. Thanks for all the enthusiasm to offer such helpful information here. Excellent information on your blog, thank you for taking the time to share with us. Amazing insight you have on this, it’s nice to find a website that details so much information about different artists . Very useful information shared in this article, nicely written! I will be reading your articles and using the informative tips. Looking forward to read such knowledgeable articles . Thankful such an extraordinary sum for this information. I have to disclose to you I concede to a couple of the centers you make here and others may require some further review, anyway I can see your perspective . 토토24 먹튀검증업체
Thank you because you have been willing to share information with us. we will always appreciate all you have done here because I know you are very concerned with our . I like your post. It is good to see you verbalize from the heart and clarity on this important subject can be easily observed.. i read a lot of stuff and i found that the way of writing to clearifing that exactly want to say was very good so i am impressed and ilike to come again in future.. Very useful post. This is my first time i visit here. I found so many interesting stuff in your blog especially its discussion. Really its great article. Keep it up. 카지노군단
Thank you so much for the post you do. I like your post and all you share with us is up to date and quite informative, i would like to bookmark the page so i can come here again to read you, as you have done a wonderful job. You have a real ability for writing unique content. I like how you think and the way you represent your views in this article. I agree with your way of thinking. Thank you for sharing. I am frequently to blogging and i genuinely appreciate your posts. This article has truly peaks my interest. I am about to bookmark your website and keep checking choosing details. 카지노
This is often just as a fantastic articles my partner and i really actually enjoyed examining. This is simply not on a regular basis that i have got prospective to work through a concern. https://mtline9.com
อยากแทงบาคาร่าออนไลน์ให้นึกถึงความหมายราคาบอลเราคัดสรร บาคาร่าออนไลน์ สุดเจ๋งมาให้เล่น ไม่ว่าจะเป็น sexy baccarat ที่มีโปรให้เลือกสรรอย่างมากมาย มีหลากหลายโปร ด้วยระบบ service ที่เปิดบริการตลอด 24 ชั่วโมง ปลอดภัยไร้กัลวล
เว็บแม่ หวยออนไลน์-ฝากขั้นต่ำ-1-บมาเองงานนี้รับรองว่า ปลอดภัย 100% ลูกค้าจะได้รับประสบการ์ณการเดิมพันที่ดี เรามีโปรโมชั่นให้เลือกมากมาย พร้อมกับการบริการตอบแทนลูกค้าที่ไว้วางใจเล่นกับเราตลอดมา
very beneficial information shared in this text, perfect written! .
I would really appreciate it Traffic Lawyer Fairfax VA if you could go into further detail. Thank you!
Correx plastic sheets are very versatile as they are water resistant, impact resistant and easy to cut to shape. These sheets really come into their own when used to protect hardwood floors from scratches during a building or renovation project. correx floor protection
Ready for an exciting leap in your Minecraft journey? Strap in, because we’re about to dive into the fresh update world of Minecraft 1.20.1! After minecraft mods
I like reading a post that can make people think. Also, thank you for allowing for me to comment!
Nice information. I’ve bookmarked your site, and I’m adding your RSS feeds to my Google account to get updates instantly.
its an amazing website, I really enjoy reading your articles.
I’d like to thank you for the efforts you have put in penning this website. I am hoping to check out the same high-grade content from you in the future as well. In fact, your creative writing abilities has motivated me to get my own blog now.
Aw, this was an extremely nice post. Taking a few minutes and actual effort to generate a top
notch article.
[url=https://www.yeezyadidas.de/]Yeezy[/url]
[url=https://www.yeezys.co/]Yeezys[/url]
[url=https://www.jordan-1.org/]Jordan 1[/url]
[url=https://www.air-jordan1.com/]Air Jordan 1[/url]
[url=https://www.nikejordan1.com/]Nike Jordan 1[/url]
[url=https://www.jordan-1s.com/]Jordan 1S[/url]
[url=https://www.jordan1.uk.com/]Jordan 1[/url]
[url=https://www.jordans-shoes.com/]Jordan Shoes[/url]
[url=https://www.jordan-shoes.us.com/]Jordan Shoes[/url]
[url=https://www.nikeuk.uk.com/]Nike UK[/url]
[url=https://www.yeezys-supply.com/]Yeezy Supply[/url]
[url=https://www.yeezy-450.com/]Yeezy 450[/url]
[url=https://www.jordanretro4.com/]Jordan Retro 4[/url]
[url=https://www.nikeoutletstoreonlineshopping.us/]Nike Outlet Store Online Shopping[/url]
[url=https://www.yeezy.uk.com/]YEEZY[/url]
[url=https://www.adidasyeezyofficialwebsite.com/]Adidas Yeezy Official Website[/url]
[url=https://www.yeezy350.uk.com/]Yeezy 350[/url]
[url=https://www.air-jordan4.com/]Air Jordan 4[/url]
[url=https://www.yeezyfoam-runner.com/]Yeezy Foam Runner[/url]
[url=https://www.yeezyslides.us.com/]Yeezy Slides[/url]
[url=https://www.ray-ban-glasses.us.com/]Ray Ban Glasses[/url]
[url=https://www.adidasuk.uk.com/]Adidas UK[/url]
[url=https://www.nflshopofficialonlinestore.com/]NFL Shop Official Online Store[/url]
[url=https://www.yeezys-slides.us.com/]Yeezy Slides[/url]
[url=https://www.yeezyadidass.us.com/]Adidas Yeezy[/url]
[url=https://www.350yeezy.us.com/]Yeezy 350[/url]
[url=https://www.yeezyy.us.com/]Yeezy[/url]
[url=https://www.yeezy350s.us.com/]Yeezy 350[/url]
[url=https://www.shoesyeezys.us.com/]Yeezy Shoes[/url]
[url=https://www.yeezys.uk.com/]Yeezys[/url]
[url=https://www.off-white.us.org/]Off White[/url]
[url=https://raybansales.us/]Ray Ban[/url]
[url=https://www.adidasyeezy.uk.com/]Adidas Yeezy[/url]
[url=https://www.yzyshoes.us.com/]Yeezy Shoes[/url]
[url=https://www.yeezy-shoes.us.com/]Yeezy Shoes[/url]
[url=https://www.yeezy-700.us.com/]Yeezy 700[/url]
[url=https://www.yeezyadidas.de/]Adidas Yeezy[/url]
[url=https://www.yeezys.co/]Yeezy[/url]
[url=https://www.jordan-1.org/]Nike Jordan 1[/url]
[url=https://www.air-jordan1.com/]Jordan 1[/url]
[url=https://www.nikejordan1.com/]Jordan 1[/url]
[url=https://www.jordan-1s.com/]Jordan 1[/url]
[url=https://www.jordan1.uk.com/]Jordan UK[/url]
[url=https://www.jordans-shoes.com/]Jordans Shoes[/url]
[url=https://www.jordan-shoes.us.com/]Jordan[/url]
[url=https://www.nikeuk.uk.com/]Nike[/url]
[url=https://www.yeezy-450.com/]Yeezy[/url]
[url=https://www.jordanretro4.com/]Jordan 4[/url]
[url=https://www.nikeoutletstoreonlineshopping.us/]Nike Outlet[/url]
[url=https://www.yeezy.uk.com/]YEEZY UK[/url]
[url=https://www.adidasyeezyofficialwebsite.com/]Adidas Yeezy[/url]
[url=https://www.yeezy350.uk.com/]Yeezy uk[/url]
[url=https://www.air-jordan4.com/]Jordan 4[/url]
[url=https://www.yeezy-supply.com/]Yeezys Supply[/url]
[url=https://www.yeezyfoam-runner.com/]Yeezy[/url]
[url=https://www.yeezyslides.us.com/]YEEZY[/url]
[url=https://www.ray-ban-glasses.us.com/]Ray Bans Sunglasses[/url]
[url=https://www.adidasuk.uk.com/]Adidas[/url]
[url=https://www.nflshopofficialonlinestore.com/]NFL Shop[/url]
[url=https://www.yeezys-slides.us.com/]Yeezys[/url]
[url=https://www.yeezyadidass.us.com/]Adidas Yeezys[/url]
[url=https://www.350yeezy.us.com/]Yeezy 350 V2[/url]
[url=https://www.yeezyy.us.com/]Yeezys[/url]
[url=https://www.yeezy350s.us.com/]Yeezy Boost 350[/url]
[url=https://www.shoesyeezys.us.com/]Yeezys Shoes[/url]
[url=https://www.yeezys.uk.com/]Yeezy[/url]
[url=https://raybansales.us/]Ray Bans[/url]
[url=https://www.adidasyeezy.uk.com/]Yeezy[/url]
[url=https://www.yzyshoes.us.com/]Yeezys[/url]
[url=https://www.yeezy-slides.org/]Adidas Yeezy Slides [/url]
[url=https://www.yeezy-shoes.us.com/]Yeezy[/url]
[url=https://www.yeezy-700.us.com/]Yeezy[/url]
[url=https://cheapyeezysonline.com/]Cheap Yeezys[/url]
[url=https://yeezysupplystore.com/]Yeezy Supply[/url]
[url=https://www.yeezyshoesonline.com/]Yeezy Shoes[/url]
[url=https://www.yeezys-supply.us.com/]Yeezy Supply[/url]
[url=https://www.yeezys-supply.us.com/]Yeezys[/url]
[url=https://www.yeezy-s.com/]Yeezy Shoes[/url]
[url=https://www.yeezy-s.us/]Yeezy[/url]
[url=https://yeezysale.us/]Yeezy[/url]
[url=https://www.pandorajewelries.us.com/]Pandora Jewelry[/url]
Tags:yeezy shoes, Yeezy, Adidas Yeezy
[img]https://www.yeezyy.us.com/images/bannerimage/b2.jpg[/img]
Our Roblox lists includes pop, rock, rap, kpop, remixes, TikTok viral sounds, cartoon songs, game songs, and much more. We have more that 10.000 Working Roblox song IDs listed. Please use the ‘Search Function’ to find your favorite songs and artists. song codes
With the update of technology,we continue to introduce three generations of coating machines,all the details as following chocolate depositor machine
Wherever you decide to live, we can ensure you’ll be living comfortably and securely. This container home is easy to deliver and assemble and comes complete with all you need to feel right at home expandable container house
we will only source from the authorized agency, distributor or original manufacturer. Feilidi Rf Modulator
we will only source from the authorized agency, distributor or original manufacturer. Feilidi Rf Modulator
Expect to hear a lot more about eCash as the network attracts more and more developers and users due to its useful features. Krypto-Wallets
The network combines years of experience with the latest technological advances Finanznachrichten
They were able to beat our pricing on stretch wrap and tape. Glad we found these guys. bubble wrap
The company integrates design, research and development, production, sales and service, focuses on technological innovation in the field of e-cigarettes, and is committed to manufacturing safe, healthy and fashionable products for global consumers. Rechargeable Electronic Cigarette
This unpredictability can lead to significant financial setbacks, testing the resolve of even the most dedicated Bitcoineers. article
We take pride in presenting our comprehensive vending services, offering an impressive array of product options to meet your diverse needs. Vending Machine Services
Customers do not need to buy servers, do not need to hire R & D staff, only need to station in the platform, can quickly implement, pay on demand use. Amazon Locker Manufacturer
Great post [url=https://2024mjs.com]먹중소[/url]! I am actually getting [url=https://2024mjs.com]먹튀중개소[/url]ready to across this information [url=https://2024mjs.com]토토사이트[/url], is very helpful my friend [url=https://2024mjs.com]먹튀검증[/url]. Also great blog here [url=https://2024mjs.com]온라인카지노[/url] with all of the valuable information you have [url=https://2024mjs.com]먹튀검증사이트[/url]. Keep up the good work [url=https://2024mjs.com]안전놀이터[/url] you are doing here [url=https://2024mjs.com]먹튀사이트[/url]. [url=https://2024mjs.com]검증사이트[/url]
Great post [url=https://wslot04.com]월드슬롯[/url]! I am actually getting [url=https://wslot04.com]슬롯사이트[/url]ready to across this information [url=https://wslot04.com]온라인슬롯[/url], is very helpful my friend [url=https://wslot04.com]온라인카지노[/url]. Also great blog here [url=https://wslot04.com]슬롯게임[/url] with all of the valuable information you have [url=https://wslot04.com]안전슬롯[/url]. Keep up the good work [url=https://wslot04.com]안전놀이터[/url] you are doing here [url=https://wslot04.com]메이저놀이터[/url]. [url=https://wslot04.com]슬롯머신[/url]
먹튀사이트
신규사이트
스포츠분석
Offer detailed guides and how-tos on various investment vehicles like stocks, digital currencies, commodities, and more. https://invest2euro.com
I wanted to thank you for this excellent read!! I definitely loved every little bit of it. I have you bookmarked your site to check out the new stuff you post vivo 20s price in pakistan
A 챔피언바둑이 Ante: Should You Pay Up?
Just saying thanks will not just be sufficient, for the fantasti c lucidity in your writing. I will instantly grab your rss feed to stay informed of any updates 레고토토
Just saying thanks will not just be sufficient, for the fantasti c lucidity in your writing. I will instantly grab your rss feed to stay informed of any updates 슈퍼헐크
I am propelled by the information that you have on this blog. It demonstrates how well you grasp this subject 캡포탈
Thank you for any other informative site. The place else could I am getting that kind of information written in such a perfect approach? I have a mission that I’m just now running on, and I have been on the look out for such info 무료 생중계
I am constantly surprised by the amount of information accessible on this subject. What you presented was well researched and well written to get your stand on this over to all your readers. Thanks a lot my dear 레모나도메인
Uncommon tips and clear. This will be to a great degree supportive for me when I get a chance to start my blog 스포츠 중계 실시간
Nice work i love your work keep it up….. 툰코
Nice work i love your w…. 툰코
hi sir you have written a very important something. I like your every point you dropped 기가평생주소
You re in purpose of actuality a without flaw website admin. The site stacking speed is astonishing. It sort of feels that you’re doing any unmistakable trap. Besides, The substance are perfect work of art. you have completed a fabulous movement regarding this matter 모모벳
I genuinely like you’re making style, inconceivable information, thankyou for posting 인천오피
Mobile Compatibility: Several cam sites have mobile-friendly versions or dedicated mobile apps, enabling users to access the platform and enjoy video chatting using their mobile device. stranger chat rooms
We provide our clients with immediate response, quick pricing and assistance in selecting equipment and arranging space on site. tutaj
By analyzing multiple websites and presenting only the most advantageous offers, the robotic system minimizes the risk of financial loss. acheter btc
Equity is an asset that is part of your net worth, making it one of the most straightforward ways to generate wealth. The Arcady
It’s essential to note that football is continually evolving, and the perception of the “best” leagues may change over time based on factors such as team performance, league competitiveness, and the emergence of new talents. serie a teams
AvaTrade is low risk as it has a trust score of 93 out of 100. AvaTrade is located in four Tier 1 jurisdictions and four Tier 2 jurisdictions. It does not operate as an institution and does not have a public listing. etherum code avis
Welcome to QualityBrokers.com – your one-stop destination for reliable, unbiased, and comprehensive reviews of online brokers in the trading world. Our mission is to empower traders and investors like you with the information and tools needed to make informed decisions and navigate the ever-changing world of financial markets confidently. website
We’re committed to delivering trustworthy and compelling news that matters to you. latest news
On the other hand, the automated mode performs analysis and executes trades when it detects a good opportunity. 88sport resena
The easy-to-win gacor site which has become a special online gacor site bookie in Asia with games. List of Gacor betting sites that are easy to win today. rtp gledek88
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I get actually enjoyed account your blog posts. Any way I will be subscribing to your augment and even I achievement you access consistently quickly. jual tanah tangerang
Common Warts that usually occur on the hands but can appear elsewhere.* wart oil
It can be a scam if you are not aware of the volatility and risks associated with Bitcoin trading. But if you are a professional, you will understand that Bitcoin and other similar unstable coins do not guarantee risk-free trading. bitcoin ifex 360 ai
If you want to video chat, Jerkay can be a good platform for you. All you need to do is stay away from fake users and scammers. luckycrush
Your equity is the amount of the property you own. Equity can increase naturally when you pay down your mortgage or when the market value of your home appreciates. It can also be given a boost by making extra payments Marina View Residences
LOGO and printing patterns can be designed according to customer requirements. Surface processes include UV screen printing, oil, frosted wrinkles, bronzing, convex, colorful freezing, crystal drops, etc. Unicorn Jewelry Box
Apart from their durability, these drawer slides come with sleek designs that improve the aesthetic appeal of the furniture. Drawer Slides Wholesale
Your substance is completely splendid from various perspectives. I think this is drawing in and educational material. Much obliged to you such a great amount for thinking about your substance and your perusers. 먹튀검증
Looking for the perfect sneaker? Read our New Balance 565 Review to discover the ideal blend of comfort and style for casual cool. Best Shoes for Capsulitis of The Second Toe
Peekaboo Sensory Book: Our soft peekaboo sensory book is designed to engage and stimulate your baby’s senses, making teething time an exciting and sensory-rich experience. baby gift sets
Shenzhen Noco Technology Co., Ltd. has warehouses nearly 5,000 square meters located in Shenzhen, Hong Kong and Singapore, which contain more than 250,000 in-stock parts. Silicon Semiconductor
Do you want to start trading Bitcoin but don’t know how to go about it? You’re in luck today because we’ve put together a brilliant tool that makes cryptocurrency trading easy. Whether you are a beginner just starting out or an experienced trader looking for a tool that will give you an edge in the highly volatile crypto market, you are invited to experience the incredible features of the Bitcoin Bank Breaker app to explore. bitcoin bank breaker
The Teething Egg: The star of our gift basket, The Teething Egg, is a revolutionary teething toy designed to soothe your baby’s sore gums effectively and safely. Its unique egg shape and soft texture provide unmatched comfort during the teething process. molar teethers
This is a detailed and comprehensive Crypto Capital (trading platform) review that will tell you everything about it, from A to Z, so let’s go ahead and investigate the legitimacy of the claims it makes. Crypto Capitale
“The way your website incorporates social media integration is a nice touch.” Partworn tyres harlow
With the innovative addition of video chat in 2010, it has become a hub for over 600 million unique connections annually, reflecting its vast global reach. Omegle
This is a detailed and comprehensive Instant Edge (trading platform) review that will tell you everything about it, from A to Z, so let’s go ahead and investigate the legitimacy of the claims it makes. bitcoin evolution recensioni
I was able to find good info from your articles.
Like!! I blog quite often and I genuinely thank you for your information. The article has truly peaked my interest.
Simply a smiling visitant here to share the love (: btw great design and style .
Good info. Lucky me I came across your website by accident.
I was able to find good info from your content.
This is a topic which is near to my heart… Cheers! Where are your contact details though?
This site certainly has all of the information I needed concerning this subject and didnt know who to ask..
Its like you read my mind!
Hello everyone today I am going to tell you that this website provides very, useful information and helpful, I hope you also like the information..
I was more than happy to search out this website.
I was able to find good info from your articles.
This is a topic which is near to my heart… Cheers! Where are your contact details though?
This site certainly has all of the information I needed concerning this subject and didnt know who to ask..
Its like you read my mind!
Hello everyone today I am going to tell you that this website provides very, useful information and helpful, I hope you also like the information..
이러한 유형의 주제를 검색하는 거의 모든 사람들에게 도움이되기를 바랍니다. 저는이 웹 사이트가 그러한 주제에 가장 적합하다고 생각합니다. 좋은 작품과 기사의 품질. 카지노사이트
One thing you’ll love about the Omegle Video chat platform is its many unique features and user-friendly design. Its robust features make it one of the best video chatting platforms out there. omegle video chat
Imagine a virtual symphony where face-to-face interactions are orchestrated in the most mesmerizing ways: Sites like Omegle
The X Bitcoin Club app allows you to monitor all your trades from a single dashboard. What’s more, you can keep track of your trades on the go thanks to the impeccable app. find out more
We developed Bitcoineer with utmost precision and accuracy. We designed Bitcoineer with the utmost precision and accuracy to help you move confidently on the best path to financial freedom. bitcoineer
We offer a yearly distribution program with extremely competitive pricing along with customized on time shipping schedules. Lm393 Voltage Comparator
Choose a sign-up bonus that perfectly suits your needs. Some will be better suited to individuals looking to place large bets, while others will be better suited to users who are more interested in playing for fun. Betting should be fun, so don’t overdo it and make reasonable bets. 토토사이트
This topic is not often discussed, so I appreciate you bringing it to light. cis returns online
Shoesguidance is a professional platform for shoe guidance and information. We strive to provide interesting and engaging content that our readers will enjoy. Shoes Review
Interested in understanding the nuances of a culture directly from someone who lives it daily? LuckyCrush acts as a conduit for such exchanges, opening doors to global insights. LuckyCrush
i am seeing new dress for girls
CFDs offer traders the flexibility to profit from both rising and falling markets, and traders can employ a variety of strategies to achieve their financial goals. bitcoinbilgileri.com/blog/cryptocurrency-arbitrage-trading